One of the most common questions in trading is how to attribute profits and losses. There are many ways of doing this each have their own advantages one of the simplest is first in first out allocation. Here is the basic concept illustrated with an example, I buy 7 apples for 10 dollars, sell 4 for 11 dollars, buy 2 more for 12 and sell 3 for 11 and then sell 2 more for 12. We can think of having a list of purchases 7,2 and list of sales 4,3,2. Each sale and purchase are associated with a price. No matter the allocation strategy, we know the profit can be calculated by a weighted sum of the sales ((4*11)+(3*11)+(2*12)) minus a weighted sum of the purchases ((7*10)+(2*12)) –> 7 dollars. Allocation tries to answer the question of which trades were bad. First in first out will allocate the first 7 sales to the first 7 purchases (7 dollars profit), leaving 2 more purchased and 2 more sold and allocate those to each other (0 profit). This tells us that all the profit was made from the first 7 purchased. However, a last in first out strategy might instead see this ((4*11)-(4*10)+((2*11)-(2*12))+((1*11)-(1*10))+((2*12)-(2*10)) which suggests that the second purchase at 12 dollars was a bad trade.
We leave the discussion for more elaborate allocation methods and their respective merits for another time. In this post we will focus on the mechanics of efficiently calculating fifo allocations. Luckily, Jeff Borror covers an elegant implementation in Q for Mortals, which I will only briefly repeat here. The idea is that you can represent the buys and sells as a matrix, where each cell corresponds to the amount allocated to that purchase and sale. By convention rows will correspond to purchases and columns to sales. So in our example, we can write the allocation as
| 4 3 2
-| -----
7| 4 3 0
2| 0 0 2
I left the corresponding order quantities in the row and columns as headers but they are actually implied. Jeff also gives us the algorithm that produces this matrix.
- First we calculate the rolling sums of the purchase and sales
- 7 9 for purchases
- 4 7 9 for sales
- We then take the cross product minimum
- 4 7 7
4 7 9
- 4 7 7
- We then take the differences along the columns
- 4 7 7
0 0 2
- 4 7 7
- We then take the differences along the rows
- 4 3 0
0 0 2
- 4 3 0
- We are done, as a bonus here is the code in Q
- deltas each deltas sums[buys] &\: sums[sells]
Not only is this rather clever, there is a certain logic that explains how to come to this result. The cumulative sums tells you how much max inventory you have bought or sold till this point. The minimum tells you how much you can allocate so far assuming you haven’t allocated anything. The differences down the columns subtracts the amount you have already allocated to the previous sales. The differences along the rows tells you how much you have already allocated to the previous purchases. Since you can only allocate what hasn’t yet been claimed.
Having read this far, you should feel confident you can easily do fifo allocations in KDB. I know, I did. There are even stack overflow answers that use this method. There is one problem, that occurs the moment you start dealing with a non trivial number of orders. This method uses up n^2 space. We are building a cross product of all the buys and sells. We know that the final matrix will contain mostly zeros, so we should be able to do better. We can use the traditional method for doing fifo allocation. Keep two lists of buys and sells allocated thus far and keep amending the first non zero element of each list and created a list of allocations triplets, (buy, sell, allocated). Although, this is linear implementing this in KDB is rather unKdb like. For incidental reasons, amending data structures repeatedly which is what this algorithm entails is best done by pointers, which in KDB means using globals and pass by reference semantics. It’s not long, but it’s not pretty.
| code | comment |
| fastFifo:{[o] | /takes orders signed to neg are sell |
| signed:abs (o unindex:group signum o); | /split into buys and sells |
| if[any 0=count each signed 1 -1;:([]row:();col:();val:())]; | /exit early if there are no buys or no sells |
| k:( | /Brains of the calculation called k (for allokate) |
| .[{[a;i;b;s] | /args are allocations triplets(a), index(i), buys(b), sells(s) |
| if[0=last[get s]&last[get b];:(a;i;b;s)]; | /if either there are no more buys or sells to allocate, return the current allocations |
| l:a[;i];l[2]:$[c:b[l 0]<=s[l 1];b[l 0];s[l 1]]; | /l is the current allocation, if (condition c) is buys are bigger allocate the sell qty, otherwise the buy qty |
| (.[a;(til 3;i);:;l+(0 1 0;1 0 0)c];i+:1;@[b;l 0;-;l 2];@[s;l 1;-;l 2])}] | /depedning on the c increment either buy or sell pointer |
| ); | /end definition of k |
| `.fifo.A set (3;count[o])#0; | /create global list of allocation triplets, size of total orders is at least 1 more than max necessary size, consider a case where you have 10 sells for 1 qty, 1 buy for 10, you will have 9 allocations |
| `.fifo.B set signed 1; | /Set the buys |
| `.fifo.S set signed -1; | /Set the sells |
| res:{delete from x where 0=0^val} update row:unindex[1] row, col:unindex[-1] col, next val from flip `row`col`val!get first k over (`.fifo.A;0;`.fifo.B;`.fifo.S); | /delete the cases of 0 allocation, return the original indexes of the orders after apply k until the allocations stop changing, return the allocations as a sparse representation of the matrix |
| delete A,B,S from `.fifo; | /delete the global variables to clean up |
| res} | /return the result |
This algorithm, has sufficient performance that we could stop there. However, we could ask is there a way to get all the benefits of the elegant array solution without paying the space cost. The answer is that we can, the trick is that as we have noticed most of the matrix will actually be filled with zeros. In particular, we can see that the matrix will essentially traverse from the top left hand corner to the bottom left hand corner. If we could split the problem into small pieces and then stitch the solutions together we would have the original path of allocations.
I will now briefly sketch out how we can split this problem into pieces and then I will present an annotated version of the code.
If we just look at the first 100 buys and first 100 sells. We can simply apply Jeff’s algorithm. If we wanted to apply it to the next 100 buys and next 100 sells, we would find that we have a problem. We need to know three things, we need to know the index of the buys and sells we are currently up to and any remaining buys and sells that we have not allocated to yet in the previous iteration. Strictly speaking we can only have unallocated quantities on one side, but it is easier to simply keep track of both and letting one list be empty each time.
Here is the annotated code:
| code | comment |
| fifoIterative2:{[o] | /takes orders signed, neg are sell |
| signed:abs o unindex:group signum o; | /split into buys and sells |
| iterate:{[a;b;s] | /Brains of the calculation called iterate takes accumulator (a), chunks of (b), chunk of sells (s), accumulator has three slots, slot 0 is for the current count where we are up to in the buys and sells, slot 1 keeps track of the unallocated qty from the previous iteration, slot 3 keeps track of the currrent allocations |
| if[any 0=sum each (b:a[1;`b],:b;s:a[1;`s],:s);:a]; | /concatenate the unallocated qty to the respective places and check if one is an empty list, if so exit early and return the accumulator |
| t:sm m:deltas each deltas sums[b]&\:sums s; | /apply Jeff’s algorithm and shrink matrix to sparse rep |
| c:(sum .[0^m;] ::) each 2 2#(::),i:last[t][`col`row]; | /Sum the last col, and last row allocated so that we can calculate the amount allocated to the last buy and sell respectively |
| a[1]:`s`b!.[i _’ (s;b);(::;0);-;c]; | /drop all the buys and sells that were fully allocated and subtract the amount allocated on the last buy and sell, from the first of what’s left assign this to slot 1, which holds the remainder |
| a[2],:update row+a[0;`b], col+a[0;`s] from t; | /Append to slot 2 the current allocations, updating the indexes using the counts from slot 0 |
| a[0]+:(`s`b!(count[s];count[b]))-count each a[1]; | /update the count, adding to the count the currently allocated and subtracing the remainder |
| a}; | /return a |
| k:max div[;200] count each signed; | /calculate the max number of rows so that each buys and sells has at most 200 elements, configurable to the maximize efficiency of the machine |
| res:last iterate/[(`s`b!(0;0);`s`b!(();());sm 1 1#0);(k;0N)#signed 1;(k;0N)#signed -1]; | /reshape the buys and sells and iterate over the chunks, select the last element which is the allocations |
| update row:unindex[1]row,col:unindex[-1] col from res} | /reindex the buys and sells into the original indexes provided by the input o |
This code actually performs much faster than the iterative version and is shorter. This code essentially has no branching except where there are no more allocations on one side and exits early.
If anyone has a better way of computing fifo allocation let me know in the comments.
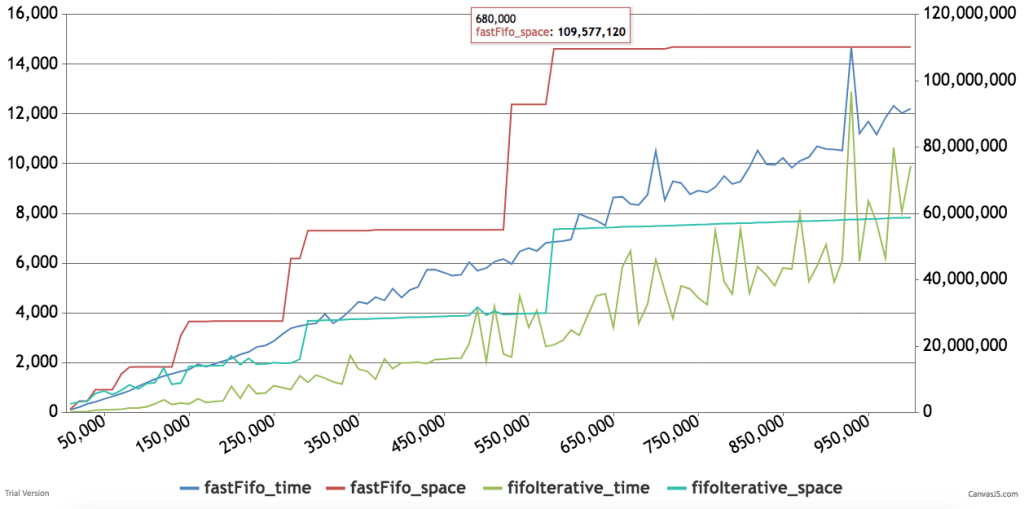
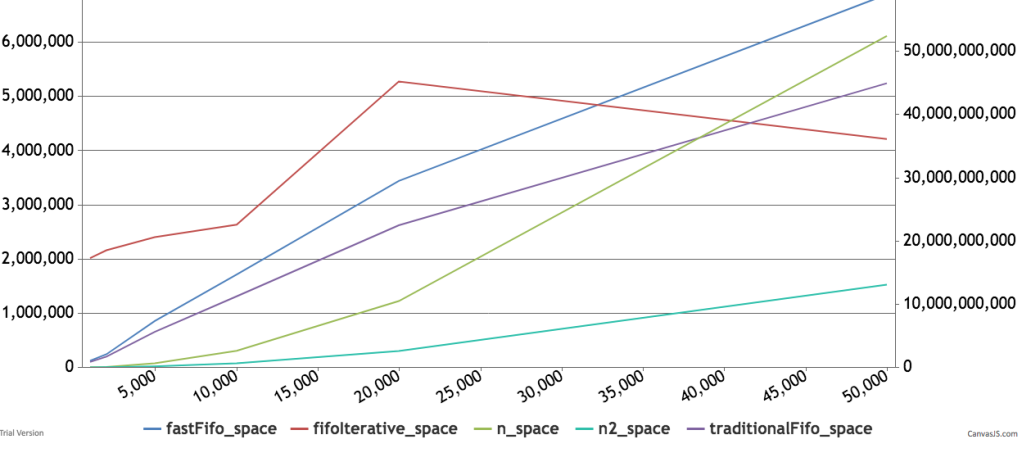
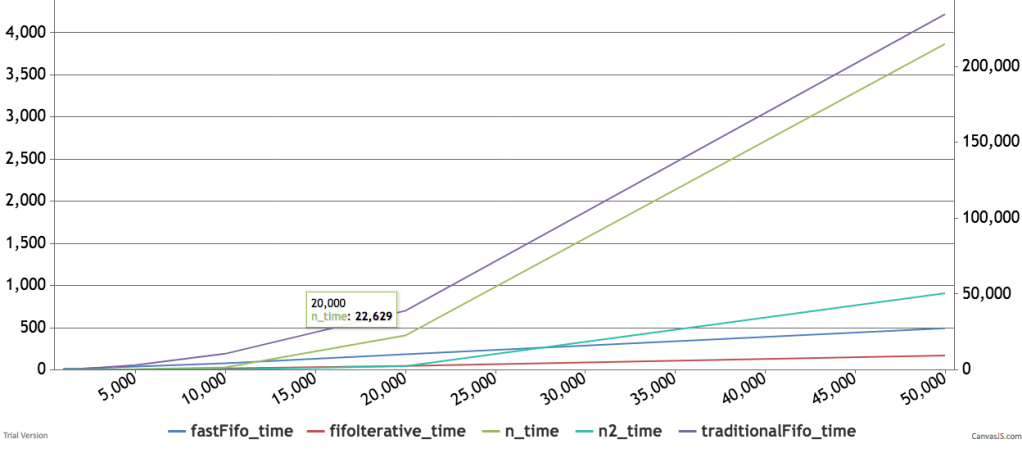
Below are some timings and graphs of memory usage. The code can be found here.