Recently, I have become a fan of Kappa Architecture. After seeing a bunch of videos and slides by Martin Kleppmann
The premise is pretty simple instead of having a batch process and a stream process. Build a stream process that is so fast it can handle batches.
Sounds simple. Well, how fast does it need to go before the difference between batch and stream is erased.
Take a simple example. Suppose I was going to start building a data processing application. In theory, I can build the following structure: A batch framework that only needs to work once and then a streaming framework that will work once the intial load is complete, and I only need to maintain the streaming framework, once I’m up and running.
Except, wait! The relevant quote is
In Theory, everything works in practice,
or my other favorite
Theory is when you know everything and nothing works. Practice is when everything works but no one knows why. In our lab theory and practice are combined: nothing works and no one knows why.
Anyway, here are three simple reasons why you this strategy fails.
- It’s possible that some producers can only produce in batches.
- Perhaps you need to reprocess the data after you change your black box
- You acquire new producers that you need to onboard.
Alright, so clearly you either need to maintain some kind of working batch processing framework. But what you don’t want is to maintain two sets of procedures that both need to be updated. That’s effectively de-normalization and it is a bad idea in databases and it is a bad idea in code (though hardly anyone talks about it).
This leads to Kappa, what if you could process everything as a stream even batches.
I imagine that this application is an island. The only way to reach the island is a stream, so if you have a truck with a ton of stuff ie a batch. We are going to unload the truck as fast as possible and send all of the stuff on tiny canoes.
So to test if this going to be scalable I decided to try some of the simplest batch files I knew. CSVs, everyone hates them but almost every system can produce them. Especially if by Comma you mean any string delimiter. Even log files can be thought of as a special case of a CSV. So can Json.
CSVs are annoying for several reasons, firstly they aren’t fixed width so there isn’t a really nice way to seek through the file without reading it. Secondly, it provides virtually no schema information.
Alright no matter, let’s see how fast we can load some pretty hefty csvs into kafka.
I try reading the csv with Python and find that on a pretty lightweight machine:
4 core, 8gb, 100gb, I can read a csv file at 100,000 lines per second. That’s pretty fast.
A 10 million row file with 30 columns can be read in 100 seconds, ~ 2gb.
That give us a gigabyte per minute. However, after adding kafka messaging overhead and playing with the batching. I can only produce about 8000 messages per second. 2 orders of magnitude slowdown.
##imports
import json as json
from kafka import SimpleProducer, KafkaClient
from datetime import datetime as dtkafka = KafkaClient([“host:9092”])
producer = SimpleProducer(kafka, async=True, batch_send_every_n=2000, batch_send_every_t=20)
def kafkasend(message):
packing = {“timestamp”:str(dt.now()), “json”:dict(zip(header, message))}
producer.send_messages(‘topic’,json.dumps(packing).encode(‘utf-8’))
I consider adding a pool of kafka producers that will each read from an in memory buffer off the csv to produce the 100,000 lines per second. But a quick calculation tells me that this is still going to be too slow. A batch process of a 2gb file should take less than 1 minute, not close to 2 minutes.
So out comes Spark. I have a small cluster of 10 machines each exactly as lightweight as the previous machine: 4 cores, 8gb, 100gb. 1gb ethernet
I fire up 15 cores, and proceed to break this 10 million row csv and send it across the wire. Here something magical happens. I can send the file in under 30 seconds, it takes some time for spark to warm up. In fact, Kafka shows that it’s recieving messages at 220mbs per second. That’s roughly 1 million messages per second during peak.
def sendkafkamap(messages):
kafka = KafkaClient([“host:9092”])
producer = SimpleProducer(kafka, async=False, batch_send_every_n=2000, batch_send_every_t=10)
for message in messages:yield producer.send_messages(‘citi.test.topic.new’, message)
text = sc.textFile(“/user/sqoop2/LP_COLLAT_HISTORY_10M.csv”)
header = text.first().split(‘,’)
def remove_header(itr_index, itr):
return iter(list(itr)[1:]) if itr_index == 0 else itr
noHeader = text.mapPartitionsWithIndex(remove_header)
import json as json
import time
from kafka import SimpleProducer, KafkaClient
from datetime import datetime as dt
messageRDD = noHeader.map(lambda x: json.dumps({“timestamp”:int(time.time()), “json”:dict(zip(header, x.split(“,”)))}).encode(‘utf-8’))sentRDD = messageRDD.mapPartitions(sendkafkamap)
This was surprising, because Jay Kreps could only get 193mb/s at the peak. And he was using machines significantly more powerful than mine on both the producer side and the kafka side. His machines had:
- Intel Xeon 2.5 GHz processor with six cores
- Six 7200 RPM SATA drives
- 32GB of RAM
- 1Gb Ethernet
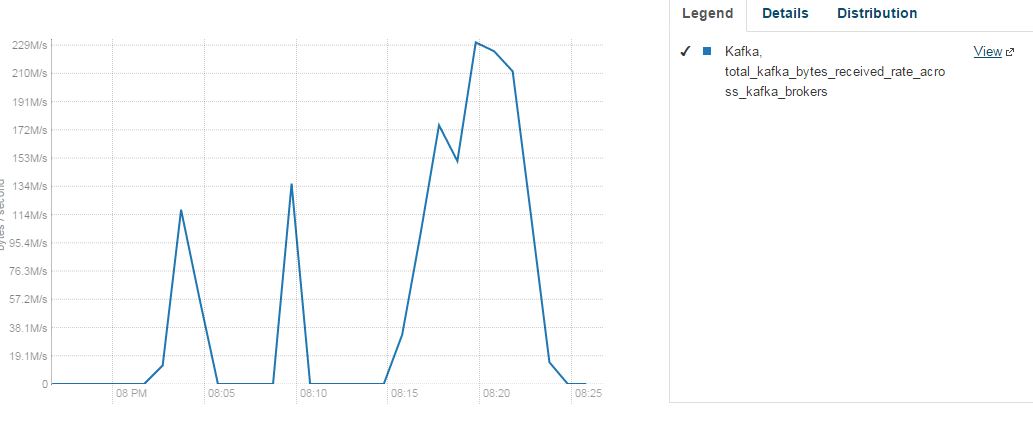
I also ran this test over and over for 14 hours, and I could maintain a write speed close to 200mbs the entire time, though I did get more spikes than he did. My machines are roughly half as powerful, which leads me to the following conclusion. The network card is the real bottle neck here. So as long as you have many producers you can scale your production until the network card is saturated long before your in memory buffer or processor cause any problems. Because there is a lot of overhead for replication and sending acknowlegments. the 220mb is probably close to the maximum. Since I was replicating it 2 more times on the two other machines. That means, while the machine was recieving 220 it was also sending 440 out. that gives you 680 of the ethernet used. Then you have to account for all of the packing the messages recieve and acknowledgments. Perhaps, with some more tuning, I could have got another 100mb in. But there is another factor at play the Spikes.
Kafka, uses a very clever piece of engineering, basically kafka pushes all of the messages out of the jvm and into the write ahead log in memory and the OS decides when to flush to disk. If the messages fill the memory too fast and the OS can’t keep up, you get a spike down. So the extra memory really just gives you a longer time for the OS to catch up and flush to disk. Of course if this is happening nonstop for 4 hours and you are streaming roughly a terabyte (at 4gb per minute you get .24 terabytes an hour). Unless, you have a terabyte of main memory, you will get spikes. Because you will need to flush main memory to disk and while that happens the OS basically prevents kafka from writing to main memory so it’s consumptions speed plummets.
Alright, so we want to process large CSVs as if they were a stream. I don’t know what is fast enough for your use case. But for me, if we can build a system that allows us to onboard a terabyte in 4 hours then we are not far behind the batch system.
Can we do better, the answer is yes.
Until now, though we had three kafka servers. Only one was doing the consuming, since I was not partitioning the messages, I was simply producing to the leader at partition 0. At this time I don’t have results from round robining to the kafka server. I will continue this train of thought in part II.

Pingback: Kafka On the Shore: My Experiences Benchmarking Apache Kafka Part II | iabdb