Now we come to one of the most innovative features in APL family of languages. That is the language feature of operators.
An operator is similar to a verb (function) but unlike a verb which produces a noun an operator always produces a verb. It’s functions is very similar to an adverb in English.
OED
Adverb
A word or phrase that modifies the meaning of an adjective, verb, or other adverb, expressing manner, place, time, or degree (e.g. gently, here, now, very). Some adverbs, for example sentence adverbs, can also be used to modify whole sentences.
I will from now on refer to operators as adverbs so that our understanding can be enhanced by our natural understanding of language. An adverb serves to help us understand how a verb will modify a noun.
For example, in the previous tutorial we saw that we can create a verb like blend which applies to some arguments. Let’s simply define blend as taking two nouns and squashing them together. For instance the blend of cat and dog is simply catdog. In fact, we have seen this type of operation earlier with the comma(,) which allowed us to append the right argument to the left argument.
q)5# reverse til 15 14 13 12 11 10 q)list1: til 10 q)list2: 5# reverse til 15 q)list3:list1,list2 q)list3 0 1 2 3 4 5 6 7 8 9 14 13 12 11 10
list3 is now the longer list that contains both list1 and list2, order is preserved. So list1 will come before list2 and all the elements in list2 will still be in their original order. So to make this a bit more interesting, let’s say that blend does something a bit different. It adds a hyphen between the two arguments.
So blend[“cat”;”dog”] will create cat-dog. Here is a simple definition for blend.
blend: {x,"-",y}
We see that blend takes two implicit arguments, x and y, adds a hyphen in between and returns one single list.
What if instead of blending two items, we wanted to blend more. We could of course create a new function called blend3 that blends three items, but K/Q is much too cool for that instead it provides an adverb over in Q and “/” in K.
So for instance in Q:
q)blend over ("cat";"dog";"mouse")
"cat-dog-mouse"
in K:
k)blend/("cat";"dog";"mouse")
So we have generalized our function from two arguments to a list. What is happening is that blend is used with the first item from the list as the first argument and the second item as the second argument. Then the result is used as the first argument and the next item on the list is used as the second. This continues until there are no more items.
To get the intermediate results we can use scan instead of over in Q and \ instead of / in K.
Here is what that looks like:
q)blend scan ("cat";"dog";"mouse"; "horse")
"cat"
"cat-dog"
"cat-dog-mouse"
"cat-dog-mouse-horse"
Now we can generalize this further. By creating a verb that is similar to what python calls join. In python the join verb takes a list of items and adds a string separator in between each item in the list. This is often needed to make comma separated lists.
Here is K/Q implementation:
join:{y,x,z}
This verb takes three arguments, the first arguments will be placed between the next two arguments.
q)join["!!!! ";"hello";"world"] "hello!!!! world"
But if we use the projection idea from before which creates another function by supplying some of the arguments. Then we can easily see how to make blend from join.
blend: join ["-";;]
so we can simply write:
q)join["-"] over ("cat";"dog";"horse")
"cat-dog-horse"
OR:
q)join[","] over ("cat";"dog";"horse")
"cat,dog,horse"
We are starting to see sentences forming in K/Q. We read sentences in English from left to right and we do the same in K/Q. The sentences are actually evaluated in right to left order. So it is correct to read it as ‘join a comma over the list’ even though K looks at it the other way.
It’s sort of like if you read the sentence
Lily jumped high over the yellow hedge.
We don’t know what she jumped over until the end yet we understand the sentence.
If we were to stage the sentence we would first need a yellow hedge then we need Lily and ask her to jump high. The staging of the sentence is how the computer interprets things, but we humans like to read sentences the first way.
This gets to a fundamental point about K/Q there are no precedence rules. The only slight exception is that you can use parentheses to force pieces of a sentence to be evaluated together, much like you would do in English with hyphenation.
For instance in this phrase:
an off-campus apartment
We could say:
an apartment that is off campus
Then we would have the same meaning without hyphens and usually if we have a choice at least in Q/K we try to rearrange things so that we don’t need to use parentheses as keeping track of how many were opened and closed is hard on the eyes and forces the reader to scan the line many times. As Donald Knuth said “Programs are meant to be read by humans and only incidentally for computers to execute.” I will have another post on K/Q style, so back to our topic.
There are only six adverbs in K/Q and a user can not make their own but they are pretty powerful and can be used in many combinations. (Technically if you add your own functions into the q.k script you can create verbs that behave very similarly to adverbs. It is not recommended unless you are an advanced user and have found some particularly useful adverbs to add to the language.)
Let’s go through them and how they work.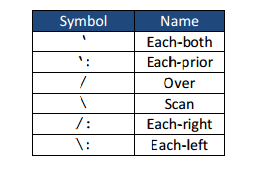
I will focus on the Q versions because the K versions are a bit harder to read. However, some functionality is only available to the symbolic representation. And each-left and each-right are not available as adverbs at all unless you use the symbolic version (even though it looks like they are from the definitions). You can always see what the K version is by simply typing the Q version with no arguments like so:
q)each
k){x'y}
q)peach
k){x':y}
q)over
k){x/y}
q)scan
k){x\y}
q)sv
k){x/:y}
q)vs
k){x\:y}
Let’s tackle the first 4 as one group and then we can go deal with the last two since they are pretty different.
Each:
Monadic
The adverb each behaves like a package inspector. If I send you a package with 3 books inside by post, I don’t expect it to be opened along the way. So if I ask the post office how many packages I sent, they should say 1. However, if I ask you how many things I sent you, you might reply 3. The package inspector is allowed to open my packages (I might not like it, but he is legally allowed). Adding each is like asking the package inspector to look inside your package and do something to each item. Note: this only removes one layer of nesting. So if I have a package with smaller boxes inside, the package inspector can only see the smaller boxes, he cannot open them.
Let’s take a simple example:
q)a:til 10 q)count a 10 q)count each a 1 1 1 1 1 1 1 1 1 1 q)type each a -7 -7 -7 -7 -7 -7 -7 -7 -7 -7h q)type a 7h
First we make a list with ten integers in it. Then we count a, we see that we have 10 items in the list. Now if we count each a. We find that we have 10 counts of 1.
Then we look at the type of each `a. Each one is a negative seven. The type of `a is positive seven. Again this makes sense, since inside of `a each item is an atom and therefore it has a negative type. `a collectively is a list of 10 atoms and therefore has a positive type.
If you have a nested list: a list of lists. You can use more than one each to reach deeper into the list. Here is an example:
q)("cat";"dog";"mouse")
"cat"
"dog"
"mouse"
q)nested:("cat";"dog";"mouse")
q)count nested
3
q)count each nested
3 3 5
q)(count each) each nested
1 1 1
1 1 1
1 1 1 1 1
q)(type each) each nested
-10 -10 -10h
-10 -10 -10h
-10 -10 -10 -10 -10h
q)type each nested
10 10 10h
q)type nested
0h
A nested list will always have type zero because it is not a simple list (one that only contains atoms of one type. There is something special that q does for a list that contains lists of one type but it only applies to tables, so we can ignore this for now) .
This was an example with a monadic verb. That is a verb that only takes one argument.
Dyadic
Let’s see a slightly more interesting example with a dyadic verb.
We have seen the verb , (append/join) which uses a comma. We now show how to combine two lists side by side. So that the first element of each list is next to each other.
q)a:til 10 q)b:reverse til 10 q)a,b 0 1 2 3 4 5 6 7 8 9 9 8 7 6 5 4 3 2 1 0 q)each[,;a]b 0 9 1 8 2 7 3 6 4 5 5 4 6 3 7 2 8 1 9 0 q)a,'b 0 9 1 8 2 7 3 6 4 5 5 4 6 3 7 2 8 1 9 0
The last two are equivalent:
q)(a,'b)~each[,;a]b 1b
The best rule, I can give about when to use each and when to use the (‘) is that if the verb is a dyadic verb then it’s better to use the (‘) because it allows a reader to see that the verb is being applied to each list item-wise. Additionally the only way to use the each with a dyadic verb is with prefix notation, with the verb and first argument passed into the each like so:
q)each[verb; first_argument] secondargument
Whereas, if you defined any verb that normally couldn’t be placed infix like so after adding the adverb it could be placed infix. Here is what I mean:
q)f:{x,y} q)"hello" f "world" 'type / we get an error we cannot / use our function infix q)"hello" f' "world" "hw" "eo" "lr" "ll" "od"
If the two lists are not the same size then each will not work. However, if one of the arguments is an atom and the other a list, then Q/K will automatically extend it.
Here is a really easy way to see this:
q)1,'b 1 9 1 8 1 7 1 6 1 5 1 4 1 3 1 2 1 1 1 0 q)enlist[1],'b 'length
In both cases, there is only a 1 in the left argument. But in the first case we have an atom so it is automatically extended. In the second case we have a list containing a 1.
Lastly, if both are atoms then the each will have no effect.
Peach/Prior:
Monadic
The command peach stands for parallel each and it behaves exactly like each except that if you start your Q/K session with multiple threads/processes it automatically will split up the work among those threads. The best way to think of this is that if you have a calculation that is fairly complex but you don’t need the result of that calculation to do the next calculation, then peach can help you out by handing out work to all of the workers. When you start a Q/K session it defaults to using only one worker. However, if you start with a -s argument followed by a positive number then you will have that number of workers. Peach let’s you easily give those workers work. In general this will only save you time if the work being handed out is significant. Since handing out the work and collecting back the results also takes time.
The easiest way to measure how much time it will take to hand out the results and get it back is to use the built in serialize and de-serialize commands. they are -9! and -8! This is how Q/K will send the data to the workers.
So a quick way to see this is to make a list of all the digits to 1 million and time how long it takes to serialize and de-serialize this cost will be for each item you send to a worker:
q)b:til 1000000 q)\t -9!-8!b 10
So this adverb is best used when the inputs and outputs are small relative to the computational work you are doing.
A really simple example is summing the cosine of the squareroot of the sine of 1 million random floats:
D:\q\w32\q.exe -s 3
q)\t {sum cos sqrt sin x?1.0} peach 3#10000000
382
q)\t {sum cos sqrt sin x?1.0} each 3#10000000
977
q)977%382
2.557592
This gives us a speed up of about 2.56. The overhead of splitting up the work takes away some of the benefit. But since I started the process with only 3 slave threads I could expect in the best case a speed up of 3. A 20% loss in overhead is pretty good, very often when you will use peach expect a much greater overhead (not a cure all).
Dyadic
There is one more use of peach which is called prior. The prior command will take a dyadic verb apply it to each pair of items in the list. Although internally peach and prior are defined the same way. Simon Garland suggested using prior when you are trying to use it this way. prior will return a list that is the same length as the input. Since there are always 1 less pair of items in a list. The first element will be enlist[0].
Here is a simple case where this is useful. You want to compare the differences between neighboring atoms in a list.
q)(-)prior til 10 0 1 1 1 1 1 1 1 1 1 /This is sometimes called deltas. /And indeed it is defined that way: q)deltas til 10 0 1 1 1 1 1 1 1 1 1 q)deltas -':
Over:
Monadic
This is possibly my favorite adverb. The idea behind over is that it calls function on the output until a stopping condition. By default if no arguments are supplied, over will keep running until one of the following conditions are met:
- The result of the ith iteration is equal to the result of the (i-1)th iteration
- The result of the ith iteration is equal to the original parameter passed to the function, within tolerance levels if floating point numbers are used. [No automatic type conversion so if a int gets cast to a float and it loops it’s never coming back.]
So for example:
q)sqrt over 100 1f
Because if you keep taking the square root of anything larger than 1 you quickly get down to 1 within some floating point tolerance.
In a loop the result before the loop is returned. For example:
q)(10 div) over 2
5
It’s pretty easy to see how this loops. If you divide 10 by 2 you get 5 and then if you divide 10 by 5 you get 2. Which is what we had before so it stops. However, this case isn’t so interesting because it stops after 1 iteration. So to show that this really works with a loop, I found an easy way to make a loop is using modular arithmetic. Modular arithmetic if you didn’t learn it in high school uses the remainder of a division. For example, 2 div 3 is 0 remainder 2. So 2 mod 3 is 2. So if we keep applying the the mod and adding 1 before applying it we will see a cycle. First I will do it by hand.
1+(2 mod 3) is 3
1+(3 mod 3) is 1
1+(1 mod 3) is 2
We have completed a cycle. So if you want to see how we can do that in Q here it is:
q){1+mod[x;3]}/ [2]
1
Okay, if you have been following along odds are you crashed your Q session quite a few times. Since getting the recursive function to not hit an infinite loop is a bit difficult. For example the following which looks very similar something I had earlier will go on forever.
Buggy CODE DON’T USE
q)(10%) over 2
The reason for this behavior is that 10%2 returns 5f and 10%5f return 2f and on and on.. Q/K doesn’t realize that the initial 2 is the same as the 2f which is a floating point 2.So if you want to do something like this you need to make sure your input is a floating point like so. q)(10%) over 2f.
One recommendation is to use the capital T parameter when you start the session or \T in the session to set an automated timeout in seconds. This should return the q session no matter what you do after the timeout. Unfortunately, this doesn’t seem to work on windows in my version (perhaps someone has better luck). Now a neat way to avoid this whole problem altogether is to specify a first parameter. However, this will only work with the / version of over and not the word version.
<digression>{I am not quite sure why the over command in q doesn’t work like the k / does, but it has to do with how Q disallows functional ambivalence. That is no monadic functions in Q are overloaded to be dyadic, in this case the / is actually over loaded from dyadic taking a verb and an argument to taking a verb a stopping condition and an argument. Q doesn’t allow for an ambivalent number of arguments even though k does in its primitives. You can always simulate this type of behavior with a dictionary by having optional arguments set inside the dictionary, however avoiding this in the language itself causes fewer bugs, since you always know how many arguments a verb needs.}</digression>
So for example; if we wanted to see the result of (10%) over 2 after 10 iterations. We could write something like:
q){10%x}/[10;2]
2f
q){10%x}/[9;2]
5f
So we can see that the 9th iteration is 5f and the tenth is 2f and this is why without a explicit stopping condition Q will loop forever. We can also substitute an expression instead of a number. Suppose we want to keep doubling a number while it is less than 100.
We could write something like:
q){2*x}/[{x<100};2]
128
For those familiar with fortran/algol inspired programming languages this is a while loop.
What you will see is that any verb {curly bracket notation} can be applied over (/) and the first argument can be also be a verb. Let’s call this first argument to over verb the running condition. This verb is evaluated and it’s output is cast to a boolean True(1b)/False(0b) if the boolean is True the loop is ran again otherwise it stops. Which is why the output is greater than 100 even though the running condition was to only run while less than 100. We keep doubling 2 until the output in this case 128 makes the verb {x<100} when cast to a boolean return 0b.
It’s important to remember that the result of this running condition verb is cast. Because Q/K assume that all non zero values are True. Which means that the verb you use as a stopping condition should return zero at some point or the loop will run forever.
BTW I call it a running condition because if it evaluates to True it runs. But you can always turn the condition into a stopping condition by placing the not verb inside the verb. Or as I choose to do create an `until verb that negates a verb.
Here are both options:
/Placing a not before the returned expression
/ makes the function read like an
/ until loop.
/So this reads like: multiply x by 2
/ until the result is greater than 100
q){2*x}/[{not x>100};2]
128
/Alternately we can create
/ an until verb which nots another verb
q)until:{not x[y]}
q){2*x}/[until {x>100};2]
128
Another note is that we can use this stopping condition functionality both infix and prefix. I use the prefix notation because I think it is easier to read. Here it is infix.
q){x<100} {2*x}/ 2 128 q)10 {2*x}/ 2 2048
Dyadic and greater
So far we covered how `over works when the function is monadic. When the function is dyadic or of a higher valence over works a bit differently.
Instead of applying the verb again and again until some stopping condition is fulfilled.
The first argument of the verb will be filled in by the first item in the list and the second by the second item. The result of this calculation will be used as the first argument in the next calculation and the next item in the list will be used as the second argument again. An easy way to see this is sum a list.
q)(+) over til 10 45 q)(+/) til 10 45
If you would like the function to start at another value for the first argument instead of the beginning of the list then you can provide that value as an atom in the first argument. This will only work with symbolic version of over (/).
q)(+/) [10;til 10] 55
If you provide a list then each atom in the list will be used as the first input in separate calculations.
q)(+/) [10 20 30;til 10] 55 65 75
If the function you want has higher valance than 2 then you will need to use the symbolic version of over (/).
Here is a simple example:
q){x+y-z}/ [0;til 10;til 10]
0
If you are using a function with higher valence then you must specify what the first argument will be and it is no longer automatically pulled from the second arguments list. The reason is that there are now two lists two choose from so pulling from either of them is ambiguous you must specify it explicitly.
Scan:
Behaves exactly like over except that it returns all the intermediate calculations as well. So for example the partial sums of a list are:
q)(+\) til 10
0 1 3 6 10 15 21 28 36 45
q)(+) scan til 10
0 1 3 6 10 15 21 28 36 45
In fact that is how sums is defined.
q)sums +\
The scan adverb is very useful for debugging the over adverb since it shows you the intermediate steps.
We can see how the modular arithmetic example proceeds.
q){1+mod[x;3]}\[2]
2 3 1
Or we can see how the division example worked:
k){10%x}\[10;2]
(2;5f;2f;5f;2f;5f;2f;5f;2f;5f;2f)
k){10%x}\[9;2]
(2;5f;2f;5f;2f;5f;2f;5f;2f;5f)
Notice how the first return of scan is the input untouched, this has two consequences. First if the return type is modified by the function as it is here (from long to float) the resulting list is a mixed type list. The second is that the length of the list of the result of a scan is 1 larger than the number of iterations the verb is applied in a while type loop. If you use scan in in the dyadic case then the length of the list will stay the same as the input list.
Here is one last example from over turned into scan we can see the powers of 2
q){2*x}\[{not x>100};2]
2 4 8 16 32 64 128
Each-Right:
Dyadic
The each-right has no command equivalent in Q. The verb sv which is defined using the symbol for each-right /: is really a verb and not an adverb.
The idea behind each-right is that it allows you to take a dyadic function and apply it to each element in the right argument. It’s equivalent to projecting the function on the first argument and then applying each to the second argument.
Here is a simple example.
q)(reverse til 10) */:til 3 0 0 0 0 0 0 0 0 0 0 9 8 7 6 5 4 3 2 1 0 18 16 14 12 10 8 6 4 2 0 q)*[(reverse til 10)] each til 3 0 0 0 0 0 0 0 0 0 0 9 8 7 6 5 4 3 2 1 0 18 16 14 12 10 8 6 4 2 0
The difference between these two is really more performance related than anything else, and it provides a shortcut so that instead of creating a projection you actually just apply the verb and the adverb. Essentially each-right will take a verb that has two arguments x and y and turn it into verb[a] each b.
Each-Left:
Dyadic
Each-left symbolized by \: and is exactly like each-right but applies to the left argument instead. Again this can be replicated by taking a dyadic verb and projecting it on the right argument and applying each on the left.
verb[;b] each a
/is equivalent to
a verb\: b
The same caveat about vs that I mentioned about sv holds true. Although vs is defined using the each-left adverb. It is not an adverb and is actually a dyadic verb.
Why do we need each-left and each-right
A quick note needs to made about the each-left and each-right adverbs, they are in some ways superfluous because of what I noted earlier which is projection of a function followed by a monadic each. However, there are times when these adverbs are useful because they allow for a very terse expression of many useful ideas. For example, there is something called the cartesian join. Ignore the name. It simply means that I want to see all the possible pairings. For example, I have hats and socks that need to be paired I don’t want to just see the ordered pairings, I want to see all of them. This complete combination has a command in Q it is called cross but we can implement it easily using adverbs (it’s actually a hair faster than the built-in command which has extra logic for tables). Here is an example:
NOTE: the RAZE is just to flatten the list into pairs of items so that we can see that all pairs are covered the real work is done by the adverbs.
q)raze (til 3),/:\:(til 3) 0 0 0 1 0 2 1 0 1 1 1 2 2 0 2 1 2 2 // this is the same as (til 3) cross (til 3)
What we see is that by chaining the adverbs together we can get something that would otherwise involve a lot of nesting and nesting is hard on the eyes. I mean here is the version using only regular each. Not only does it involve creating a verb, you also need to project that verb twice in two different ways.
q)raze {,[x;] each y} [;til 3] each til 3 0 0 0 1 0 2 1 0 1 1 1 2 2 0 2 1 2 2
Readability is the primary reason for using each-left and each-right. When we get to q-sql we will come across tables that have rows with lists inside, I will not try to explain tables here, but I want to give at least one more example where each-left is useful.
q)select from t where a~\: til 10
a
-------------------
0 1 2 3 4 5 6 7 8 9
q)select from t where ~[;til 10] each a
a
-------------------
0 1 2 3 4 5 6 7 8 9
/ these second two examples show
/ how you can find out
/ if two lists are element equivalent
/ this is important if you don't know the types
/ but care only about the values
q)select from t where {min x=y}[;til 10] each a
a
-------------------
0 1 2 3 4 5 6 7 8 9
q)select from t where a{min x=y}\:til 10
a
-------------------
0 1 2 3 4 5 6 7 8 9
Summary:
I think I’ll summarize this whole tutorial with an example that is close to my heart and uses many of the things we learned so far. The problem is calculating stationary probability matrices. (This is one of those times where I am using math that is way beyond high school level but perhaps you’ll forgive me). Let me give a brief sketch of the problem and then you’ll see why it’s a perfect candidate for many of the above adverbs and it is something worth parallelizing.
I will give a very simple to understand example of a Markov chain. If you remember Chutes and Ladders or Snakes and Ladders the game, then this will be easy to explain.
From Wikipedia:
Each player starts with a token on the starting square takes turns to roll a single die to move the token by the number of squares indicated by the die roll. Tokens follow a fixed route marked on the gameboard from the bottom to the top of the playing area, passing once through every square. If, on completion of a move, a player’s token lands on the lower-numbered end of a “ladder”, the player must move the token up to the ladder’s higher-numbered square. If the player lands on the higher-numbered square of a “snake” (or chute), the token must move down to the snake’s lower-numbered square.
We can think of the probability of getting from any square to any other in the next move as a table with the rows representing the current square (more generally this is called a state) and the columns representing the next square.
By this definition every row will sum to 1 since the probability of going to any of the possible squares must be 1 since you must land on some square at the end of a turn.
What’s interesting about this representation is it allows us to calculate the probability of being in a particular square after two turns simply by multiplying the table with itself (I will spare you the details of matrix multiplication assume it is built in. The command is called mmu which stands for matrix multiply). In general the probability of being in a particular square after n moves is equivalent to multiplying the matrix with itself n times.
One final interesting property has been shown, if you have this table with the probability of going from one square to another and these probabilities don’t change. Then you can calculate the probability of being in any square without knowing anything about where you are now. This is because if you keep multiplying the matrix with itself every row will have the same numbers. Which means it doesn’t matter where you started the long term probability of being on a particular square is the same. In Chutes and Ladders we actually know what that is. It’s the final square, that is where the game ends so if you land on that square you stay there forever.
So the first thing I want is a verb that given a number (x) of states generates a valid probability table. I will call it markgen. I know that this probability table is going to be square. So we square x and assign it to n. I can generate n random numbers that are below n like so n?n. I can then reshape it into a square table by using the take verb(#). So that becomes (x;x)#n?n. We will call this m:(x;x)#n?n. We now have a x by x table full of random numbers. We need the rows to sum to 1. We need to sum the rows which we can do by summing each m. Since by default the sum command will sum the columns. We can actually do this another way by flipping m and then summing, but it turns out that each is faster (it’s always good to check these things).
Then we need to divide each row in m by it’s row’s sum. That looks like m %’ sum each m. So the whole verb that generates markov matrices is:
q)markgen:{n:x*x; m:(x;x)#n?n; m%' sum each m}
As you can see we used two each adverbs. Once to sum each row and the second time to divide each row in m by the row sum. When we use it with the division symbol because division is dyadic we must use the tick mark next to it.
The next part is to calculate the stationary probability (sp) matrix. This is pretty easy we just need to keep multiplying the matrix with itself until it stops changing. If m is our matrix that looks like mmu[m;] over m. Since we know that all the rows will be the same we can just return the first row. The whole sp verb looks like:
q)sp:{[m] first mmu[m;] over m}
Now suppose we wanted to create a bunch of these matrices and find the stationary probability. We can do this by creating a list of the same number using the take verb. So that would be 6#10 gives us 10 10 10 10 10 10. We want to run this whole process on each of these numbers so we will need the each or peach command.
{sp markgen x} each 6#100
or
{sp markgen x} peach 6#100
This will give us 6 rows each row representing the stationary probability of each matrix we created.
Now we can use the timing command to see what the difference between each and peach is. Make sure to start your q session with the -s flag followed by the number of threads.
q.exe -s 3
q)\t {sp markgen x} each 300#100
2406
q)\t {sp markgen x} peach 300#100
1006
Which gives about a 2.39 speedup which means we lost about 20% in overhead.
In practice we probably wouldn’t create random matrices but we could use it to show why the Snakes and Ladders always ends pretty quickly.
Let’s create a random board but add one condition, the one actually present in the game. We will replace the last state with one that stays there. This is because if you make it to end of the board you stop rolling the die and stay there.
q)l:markgen 10 / here we will replace the 10th row with a row of zeros followed by a 1. /the idea is that if you are in this square you always go back to it. q)l[9]:(9#0f),1f q) l
0.0234375 0.1640625 0.1933594 0.09765625 0.0546875 0.1796875 0.1132813 0.08984375 0.08398438 0 0.04945055 0.1794872 0.1135531 0.1739927 0.001831502 0.08974359 0.09157509 0.0989011 0.03663004 0.1648352 0.09722222 0.1163194 0.04513889 0.005208333 0.1545139 0.03993056 0.125 0.1440972 0.1388889 0.1336806 0.0977918 0.09305994 0.137224 0.06466877 0.1041009 0.1230284 0.1435331 0.05520505 0.1198738 0.0615142 0.1304348 0.08937198 0.1086957 0.1280193 0.1980676 0.01690821 0.08695652 0.1207729 0.1014493 0.01932367 0.02894737 0.2105263 0.09473684 0.1578947 0.04736842 0.04473684 0.1315789 0.1684211 0.06842105 0.04736842 0.06174957 0.09090909 0.006861063 0.05317324 0.06003431 0.09948542 0.1320755 0.1578045 0.1698113 0.1680961 0.1029412 0.1386555 0.1323529 0.1008403 0.1239496 0.03361345 0.006302521 0.05672269 0.1848739 0.1197479 0.08868502 0.009174312 0.0795107 0.07033639 0.1314985 0.2293578 0.06116208 0.01223242 0.2996942 0.01834862 0 0 0 0 0 0 0 0 0 1
q)sp l
0 0 0 0 0 0 0 0 0 1f
What we see is that if there is a way to get into a square that can’t transition then the long term probability is that you will always end up there. We can generate random boards with this property and see how long it takes to converge this would be a measure of the average number of turns you need before the game ends.
q)count mmu[l;] scan l
8232
This board looks like it would take a really long time before the game ended.
Next time we’ll look a bit deeper at tables and dictionaries.
